Some intuitions about large language models
An open question these days is why large language models work so well. In this blog post I will discuss six basic intuitions about large language models. Many of them are inspired by manually examining data, which is an exercise that I’ve found helpful and would recommend.
Language models are pre-trained to simply predict the next word in a corpus of text, and they learn a surprising amount from this. Let’s look at some examples of what they might learn from this next-word prediction task.
Intuition 1. Next-word prediction on large, self-supervised data is massively multi-task learning.
Although next-word prediction is an extremely simple task, when combined with massive datasets, it forces the model to learn a lot of tasks. Consider the following examples of traditional NLP tasks that can be learned by predicting the next word on some text in the corpus.
| Prefix {choice_1, choice_2} | Task |
|---|---|
| In my free time, I like to {run, banana} | Grammar |
| I went to the zoo to see giraffes, lions, and {zebras, spoon} | Lexical semantics |
| The capital of Denmark is {Copenhagen, London} | World knowledge |
| I was laughing the entire time, the movie was {good, bad} | Sentiment analysis |
| The word for “pretty” in Spanish is {bonita, hola} | Translation |
| First grade arithmetic exam: 3 + 8 + 4 = {15, 11} | Math question |
The above tasks are clear-cut but a bit idealized. In reality, predicting the next word involves doing many “odd” tasks. Consider the following sentence:
| Prefix | Next word [task] |
|---|---|
| A transformer is a deep learning architecture, initially proposed in | 2017 [factual recall] |
| A transformer is a deep learning architecture, initially proposed in 2017 | , [comma prediction] |
| A transformer is a deep learning architecture, initially proposed in 2017, | that [grammar] |
| A transformer is a deep learning architecture, initially proposed in 2017, that | relies [impossible task?] |
When you view the data in this way, it is obvious that next-word prediction forces the model to learn a lot about language; not just syntax and semantics, but also things like comma prediction, factual knowledge, perhaps even reasoning. This is an interesting example of how a simple objective, when combined with complex data can lead to highly intelligent behavior (assuming you agree that language models are intelligent).
Intuition 2. Learning input-output relationships can be cast as next-word prediction. This is known as in-context learning.
The past decades of machine learning have focused on learning the relationships between <input, output> pairs. Because next-word prediction is so general, we can easily cast machine learning as next-word prediction. We call this in-context learning (a.k.a. few-shot learning or few-shot prompting). This was pioneered by the GPT-3 paper, which proposed using a natural language instruction following by <input, output> pairs. This is shown in the left image below from the GPT-3 paper.

In the right part of the image above, we can see that increasing the number of examples in context improves performance for a task in the GPT-3 paper. This means that the model benefits from seeing these <input, output> examples.
In-context learning is a standard formulation of using large language models that is convenient because <input, output> pairs were how we did machine learning for the past decades. However, there is no first-principles reason why we continue following <input, output> pairs. When we communicate when humans, we give also them instructions, explanations, and teach them interactively.
Intuition 3. Tokens can have very different information density, so give language models time to think.
It is a fundamental truth that not all tokens are worth the same in terms of information.
Some tokens are very easy to guess and not worth much at all. For example, in “I’m Jason Wei, a researcher at OpenAI working on large language ___”, it’s not so hard to predict “models”. It’s so easy to predict that token that not much information is lost if I omit it.
Some tokens are very hard to guess; they’re worth a lot. For example, in “Jason Wei’s favorite color is ___”, it’s virtually impossible to predict. So that token contains a lot of new information.
Some tokens can also be very hard to compute. For example, in “Question: What is the square of ((8-2)*3+4)^3/8? (A) 1,483,492; (B) 1,395,394; (C) 1,771,561; Answer: (”, the next token requires a lot of work (evaluating that expression).
You can imagine that if you’re ChatGPT, and as soon as you have to see the prompt you have to immediately start typing, it would be pretty hard to get that question right.
The solution to this is to give language models more compute by allowing them to perform natural language reasoning before giving the final answer. This can be done via a simple trick called chain-of-thought prompting, which encourages the model to reason by providing an example of a “chain-of-thought” in the few-shot example, as highlighted in blue.
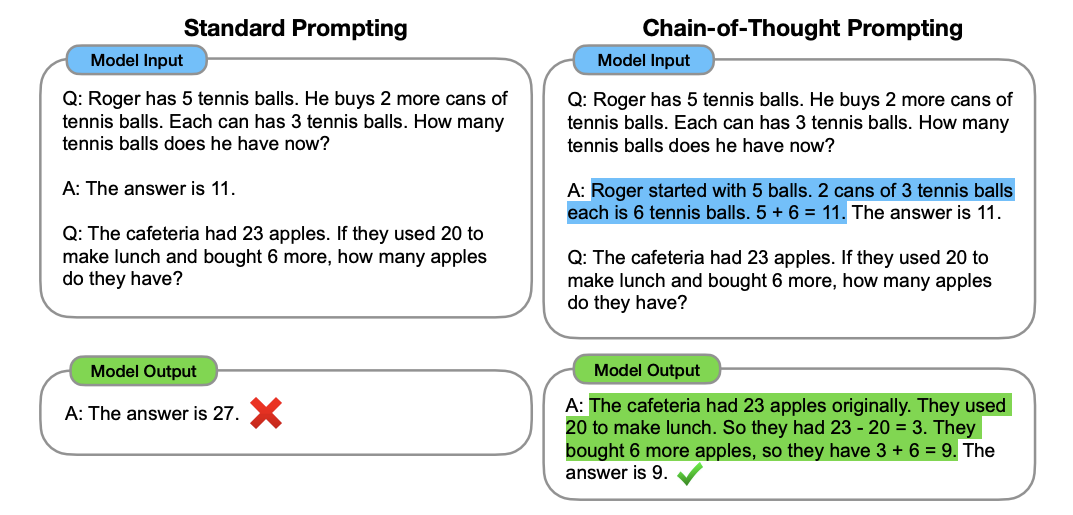
This technique is really useful for improving performance on complicated reasoning tasks that would require humans to spend more than one second solving. For even-more-complicated problems than the simple arithmetic problem shown above, it can help to have the language model decompose the prompt first into subproblems, and then sequentially solve the subproblems (“least-to-most prompting”). This paradigm is powerful because we want AI to eventually be able to solve the hardest problems we face as humans (e.g., poverty, climate change, etc), and being able to reason is a fundamental building block for solving such problems.
The key reason that the above next-word prediction tasks work is scaling, which means training larger neural nets on more data. Obviously it costs a lot of money to train frontier language models, and so the reason we do it is that we have reasonable confidence that using larger neural networks and more data will actually lead to a better model (i.e., performance probably won’t saturate when you increase the model and data size).
Intuition 4. Scaling language models (size and data) is expected to continue improving loss.
The fact that scaling improves performance predictable is called “scaling laws”, for which the left figure below shows that as you increase compute, test loss improves smoothly.

The right figure is another piece of evidence of how loss smoothly improves as you scale up the language model—by tracing the loss curve of smaller models, you can predict GPT-4’s loss using up to 10,000x less compute.
It is an open question why exactly scaling works, but here are two hand-wavy reasons. One is that small language models can’t memorize as much knowledge in their parameters, whereas large language models can memorize a huge amount of factual information about the world. A second guess is that while small language models are capacity-constrained, they might only learn first-order correlations in data. Large language models on the other hand, can learn complex heuristics in data.
Intuition 5. While overall loss scales smoothly, individual downstream tasks may scale in an emergent fashion.
Let’s take a closer look at what exactly happens when loss improves. You can consider overall loss as a weighted average of the massive amount of tasks learned, e.g.,
Overall loss = 1e-10 * (loss of grammar task) + 1e-10 * loss (loss of sentiment analysis task) + …
+ 1e-10 * (loss of math ability task) + …
Now consider your loss going from 4 to 3. Do all tasks get better uniformly? Probably not. Maybe the grammar of the model with loss = 4 was already perfect, so that is saturated, but the math ability improves a lot in the model with loss = 3.
It turns out that if you look at the performance of the model on 200 downstream tasks, you’ll see that while some tasks smoothly improve, other tasks don’t improve at all, and some tasks improve suddenly. Here are eight examples of such tasks, where performance is about random for small models, and increases to well above random once the model size reaches a certain threshold.
The term we use for qualitative changes arising from quantitative changes is “emergence”. More specifically, we call an large language model ability emergent if it is not present in smaller models, but is present in larger models. In such tasks, we often see that performance is about random for small models and well above random for models larger than a certain threshold size, as shown in the figure below.

There are three important implications of emergence:
Emergence is not predictable by simply extrapolating scaling curves from smaller models.
Emergent abilities are not explicitly specified by the trainer of the language model.
Since scaling has unlocked emergent abilities, further scaling can be expected to further elicit more abilities.
Intuition 6. Real in-context learning happens, but only in large-enough language models.
We have seen from the GPT-3 paper that increasing the number of in-context examples improves performance. While we hope that it is because the model actually learns <input, output> mappings from the examples in its context, the improvement in performance could be due to other reasons, such the examples telling the model about formatting or possible labels.
In fact, one paper showed that GPT-3’s performance barely decreases even if you use random labels for the in-context examples. They suggest that performance improvement is hence not due to learning <input, output> mappings, but rather due to the in-context examples teaching things like formatting or the possible labels.
However, GPT-3 is not a super “large” language model compared to the most powerful models today. If we take a more extreme setting of flipped labels (i.e., positive means negative and negative means positive), then we find that large language models strongly follow the flipped labels, while small language models aren’t affected by performance at all. This is shown in the below figure, where performance dips for the large language models (PaLM-540B, code-davinci-002, and text-davinci-002).

The takeaway here is that language models do look at <input, output> mappings, but only if the language model is large-enough.
Closing
I hope the above intuitions were useful despite how basic they are. One theme that is common across many of the intuitions is that you can learn a lot by manually looking at data. I enjoyed doing this recently and highly recommend it :)